While some of us may disagree, I think XML is a great method of moving small-to-medium sized data sets into SQL Server.
Because of XML’s generality, it can be used by pretty much any client application and technology you can think of, and this can be a big advantage to getting the job done quickly and flexibly. I personally like it most for passing in sets of parameters (i.e., multiple ids) into stored procedures, and sending in full sets of data values where it’s much easier to consolidate them on the SQL side rather than using complicated application logic.
The downside is that the XML has to be shredded (i.e. parsed) on the SQL Server side, which uses CPU. Out of all the tiers in our application stack, SQL Server is the most expensive to scale up, so it’s important to be mindful when putting operations with large processing overhead into production. Ideally, we’d like to use XML with as little overhead as possible.
When we tell SQL Server to shred an XML document into a rowset, it can’t make assumptions about what the incoming XML is going to look like. In fact, by default, SQL Server assumes there could be multiple root elements in the document (i.e., it’s an XML fragment)!
By using XML Schema Collections, we tell SQL Server what to expect, and the optimizer is able to tailor the query plan to only include the necessary physical operations. A great side-effect of this is that the incoming XML is automatically validated against the schema, essentially making the input “strongly typed” like we would with regular variables.
Let’s walk through an example to demonstrate just how much of a difference this can make. (Note: XML Schema Collections are available in 2005+, but this example code is written for 2008+.)
First, I’ll create a table into which I’ll dump the shredded data:
CREATE TABLE [dbo].[Table1] ( Id int IDENTITY(1, 1) PRIMARY KEY CLUSTERED, Value1 int NOT NULL, Value2 nvarchar(50) NOT NULL );
Next, I’ll create the XML Schema Collection for comparison testing. You can see all the XML Schema Collections in a database through Management Studio in the Programmability | Types | XML Schema Collections folder.
CREATE XML SCHEMA COLLECTION [dbo].[Table1Rows] AS N'<?xml version="1.0"?> <xs:schema attributeFormDefault="unqualified" elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="Table1Rows"> <xs:complexType> <xs:sequence> <xs:element maxOccurs="unbounded" name="Table1Row"> <xs:complexType> <xs:sequence> <xs:element name="Value1" type="xs:integer" minOccurs="1" maxOccurs="1" /> <xs:element name="Value2" type="xs:string" minOccurs="1" maxOccurs="1" /> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>';
Finally, here is the meat of the test script, which builds up an XML document, and then shred/INSERTs it into the table. Comparison test by uncommenting the (Table1Rows) part of the XML variable declaration on line 15.
DECLARE @sourceString nvarchar(MAX) =
CONVERT
(
nvarchar(MAX),
(
SELECT TOP 100
CAST(v.number AS nvarchar(4)) AS Value1,
REPLICATE('a', CAST((v.number / 50) AS int)) AS Value2
FROM master..spt_values v
WHERE v.type = 'P'
FOR XML PATH('Table1Row'), ROOT('Table1Rows')
)
);
DECLARE @sourceXml xml/*(Table1Rows)*/ = @sourceString;
DECLARE @i int = 100;
DECLARE @startTime datetime2;
DECLARE @endTime datetime2;
SET NOCOUNT ON;
TRUNCATE TABLE [dbo].[Table1];
SET @startTime = SYSDATETIME();
WHILE @i >= 0
BEGIN
INSERT INTO [dbo].[Table1](Value1, Value2)
SELECT
n.x.value(N'Value1[1]', 'int'),
n.x.value(N'Value2[1]', 'nvarchar(50)')
FROM @sourceXml.nodes(N'Table1Rows[1]/Table1Row') n(x);
SET @i -= 1;
END
SET @endTime = SYSDATETIME();
SELECT DATEDIFF(MILLISECOND, @startTime, @endTime);
While the results on your machine will no doubt vary versus mine, my test on a 2008 R2 instance took about 3,100 milliseconds without using the XML Schema Collection, and about 280 ms with. This is a huge improvement! And we can see the difference in the query plans.
Before:
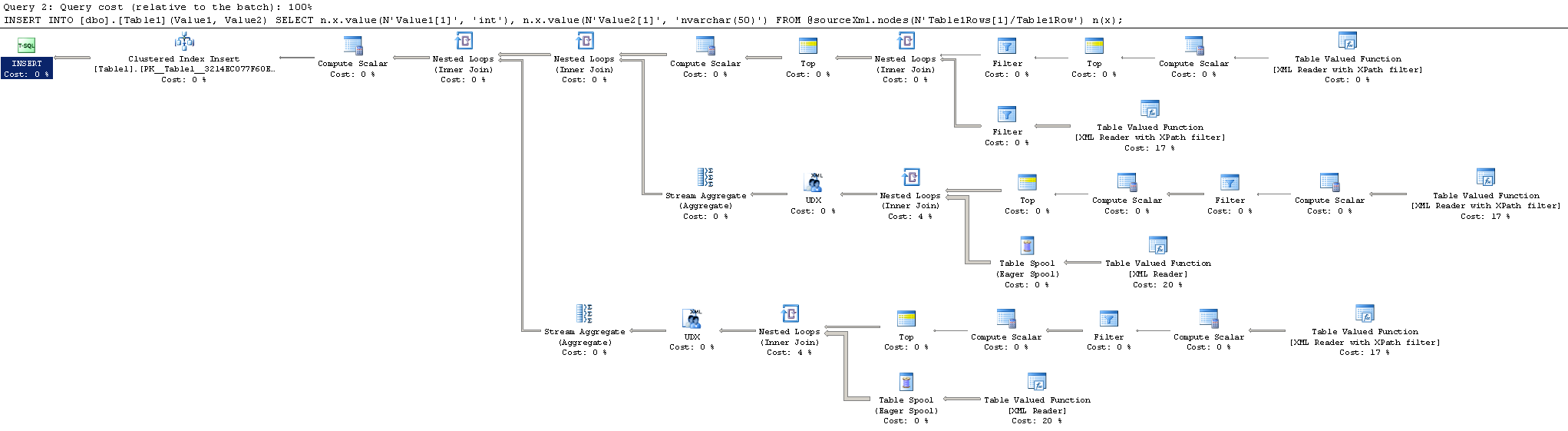
After:

When I started using XML Schema Collections, I was only using them to strongly-type my XML, but it turns out that shredding XML can see a significant performance improvement as a side-effect. I read that strongly-typing XML slows down writes to XML variables, but I have yet to encounter a situation where that was necessary, or indeed, a good idea.
If you do start using XML Schema Collections in your own applications, I have a slight caution: you may want to avoid strongly typing parameters that are exposed in the database API (i.e., stored procedure parameters), even though it’s technically correct to construct the parameters that way. The reason why is that XML Schema Collections, once created, cannot be altered in-place (there is an ALTER XML SCHEMA COLLECTION, but it doesn’t do what you might expect). To change the definition, a collection must be dropped and recreated, which means that all objects with strong dependencies must be dropped and recreated as well. I think this is a royal pain — feel free to vote up the Connect feature request to add the expected functionality.
A workaround is to weakly type the API parameters, but immediately cast the parameter to a strongly-typed local variable in the procedure body, like so:
CREATE PROCEDURE [dbo].[Proc1](@p1 xml) AS BEGIN DECLARE @realP1 xml(MySchemaCollection) = @p1; ...
From an API point of view, that’s not the best solution as the strong type isn’t exposed to the outside, but IMO, it’s a good enough tradeoff from a maintenance point of view, particularly if the Schema Collection is reused in many places.


