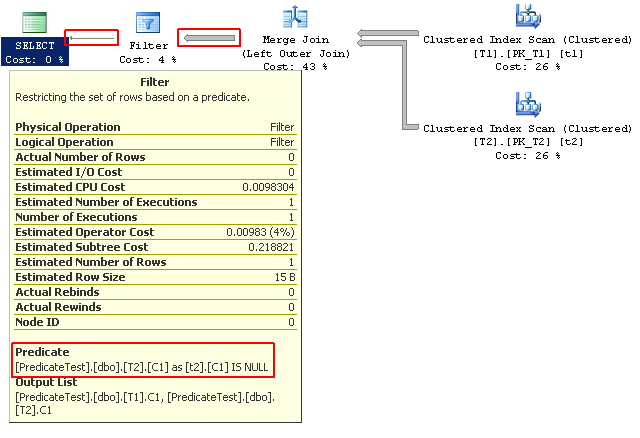
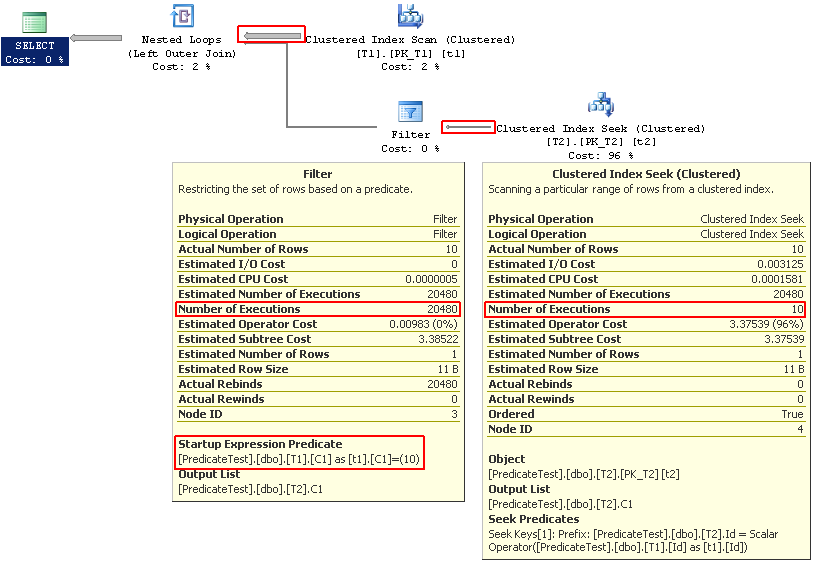
Sometimes we face the requirement to search a table for a specific string value in a column, where the values are very long. The default answer is to create an index, but we must remember that index keys cannot exceed a 900-byte size limit, and LOB columns (which include the MAX type variants) cannot be in the index key at all. In this post, we’ll explore a method to efficiently index long character strings where the search operation is moderately-to-highly selective.
The Methodology
Since we’re faced with a size restriction on the index key (or the string column cannot be included in the key at all), we need to apply some kind of transformation to the string data to make its representation — and hence the index key size required — smaller.
Of course, we can’t simply compress an infinite amount of data into a comparatively very small field, so the index we create won’t be able to support all the same operations as if we had indexed the original field. But most of the time, that isn’t a problem — generally, we need to search for an exact match, or a string starting (or maybe even ending) with a given few characters.
We’re going to do this by performing a computation on the original values, storing the result in a new column in the table, and creating an index on that column (there are two ways to do this, which we’ll get into shortly). In terms of the computation itself, there are a few different options that can be used, depending on what needs to be accomplished. I’ll introduce two basic approaches here, and then we’ll run through some code that demonstrates one of them.
- Use the LEFT function to grab the first several characters and discard the rest. This method is appropriate for both exact matching and wildcard searching with a few given characters (i.e., LIKE ‘abc%’), and because the original text stays in tact, it supports case/accent-insensitive matching without doing anything special. The drawback of this method, though, is that it’s really important to know the data. Why? To improve the efficiency of queries, the number of characters to use should be enough such that the computed values are more or less unique (we’ll see why in the example). It may in fact be the case that the original field always has a consistent set of characters at the beginning of the string (maybe they’re RTF documents or something), so most of the computed values would end up being duplicates (if that’s the case, this approach won’t work and you’ll want to use the other approach instead).
- Use a traditional hash function (such as HASHBYTES) to compute a numeric representation of the original field. This method supports exact matching (case-insensitivity with a small tweak, and accent-insensitivity with a bit of code), but not partial matching because the original text is lost, and there’s no correlation between the hash value and the original text. It’s also critical to watch the data types involved here, because hash functions operate on bytes, not characters. This means hashing an nvarchar(MAX) value N’abc’ will not give the same result as hashing a varchar value ‘abc’, because the former is always 2 bytes per character. Those are the downsides. The upside is that traditional hashing has the ability to work on data that contains very few differences, and when the text starts with the same sequence of characters.
Both of these methods are hash functions, as they convert a variable length input to a fixed length output. I suppose the first approach isn’t technically a hash function because the input could be shorter than the number of characters desired in the output, but I think you see my point that both approaches “sample” the original data in a way that allows us to represent the original value more or less uniquely without needing to carry around the original data itself. Maybe it’s more correct to speak of them as lossy compression algorithms. In any event, I will refer to the results of these functions as hash values for the remainder of the post.
Because this method omits some (or probably most) of the original data, some extra complexity in our code must be introduced to compensate for the possibility of duplicate hash values (called a hash collision). This is more likely to happen using the first approach as the original data values are partially exposed. It’s still possible, however rare, that the second approach can have duplicates, too, even if the input text is unique, so we must accommodate for that.
Speaking specifically about using a traditional hash function, such as HASHBYTES, there are a couple major things to consider. First, there are several different algorithms to choose from. Because we aren’t going to be using the hash value for any type of cryptographic functionality (i.e., we don’t care about how difficult it will be to “unhash” the values), it’s largely irrelevant which algorithm we choose, except to pick one that produces a hash value of an acceptable size. A larger hash value size will reduce the possibility of collisions as there are more possible combinations, but as I already mentioned, we have to handle for collisions anyway because no hash function is perfect; therefore, it’s okay to use a smaller hash value size to save storage space, and pick a hash algorithm that is least expensive to compute initially.1
Second, we need to make sure that the hash values represent a consistent portion of the string input values. HASHBYTES is great because it’s built-in, but its input parameter is limited to 8000 bytes. This means if the string values needed to be hashed are longer than 8000 char/4000 nchar, a slightly different approach should be taken. I would recommend creating a CLR scalar function, as there are no limitations of input size in the .NET hashing classes.
The Test
As I mentioned previously, there are two ways to store the hash values so they can be indexed:
- Computed column. This method has two advantages: first, the SQL Server engine automatically keeps the hash value up-to-date if the source column changes. Second, if we use a non-PERSISTED column, we save the storage space for the hash values in the base table. The main disadvantage is that we may have to poke and prod our SQL statements to get the plan shape we want; this is a limitation of computed columns in general, not of what we’re doing here specifically. Note: if your goal is to create hash values in two tables and JOIN them together on that column, it may not be possible to do it efficiently using computed columns because of bizarre optimizer behaviour. Any time computed columns are involved, always inspect the execution plan to make sure SQL Server is doing what’s expected — sometimes common sense doesn’t make it into the execution plan that gets run.
- Base table column, updated by triggers (if required). This method works best to get execution plan shapes that we want, at the expense of a bit of complexity to keep the values updated, and the additional storage space required in the base table.
In the example below, we’ll use the base table column method, as it’s the most flexible, and I won’t have to go into detail about hinting in the SQL statements.
Let’s start by creating a table to play with:
CREATE TABLE [dbo].[Table1]
(
Id int NOT NULL IDENTITY
PRIMARY KEY CLUSTERED,
StringCol varchar(MAX) NOT NULL
);
GO
And then we’ll populate it with some test data (note: the total size of the table in this demo will be about 70 MB):
SET NOCOUNT ON;
GO
INSERT INTO [dbo].[Table1](StringCol)
SELECT
REPLICATE('The quick brown fox jumps over the lazy dog. ', 5) +
CONVERT(varchar(MAX), NEWID())
FROM master..spt_values v
WHERE v.type = 'P';
GO 64
INSERT INTO [dbo].[Table1](StringCol)
VALUES ('The quick brown fox jumps over the lazy dog.');
GO 3
So we’ve got about 130,000 random-type strings, and then 3 rows which we can predict. Our goal is to efficiently find those 3 rows in the test queries.
Since the string field was defined as varchar(MAX), we can’t create an index on that column at all, and the only index we have in the base table is the clustered index on the Id column. If we try a naive search at this point, we get a table scan, which is the worst case scenario:
DECLARE @search varchar(MAX) =
'The quick brown fox jumps over the lazy dog.';
SELECT Id, StringCol
FROM [dbo].[Table1]
WHERE StringCol = @search;

We get our 3 rows back, but this is far from ideal. I’m not sure why the optimizer chooses a scan and filter instead of pushing down the predicate into the scan operator itself, but that’s beside the point because this is an awful plan, with an estimated cost of over 3.5.
Let’s move on and create our hash value column and populate it. Note that if you want to update the hash values using triggers and keep the column NOT NULL, you’ll need to add a default constraint so INSERTs don’t fail outright before the trigger code gets a chance to run.
ALTER TABLE [dbo].[Table1]
ADD StringHash binary(16) NULL;
GO
UPDATE [dbo].[Table1]
SET StringHash = CONVERT(binary(16), HASHBYTES('MD5', StringCol));
GO
ALTER TABLE [dbo].[Table1]
ALTER COLUMN StringHash binary(16) NOT NULL;
GO
We have our hash values in the table, but still no index to improve our query. Let’s create the index now:
CREATE NONCLUSTERED INDEX IX_Table1_StringHash
ON [dbo].[Table1](StringHash);
While this looks unremarkable, the index has been created non-unique on purpose — first and foremost to accommodate duplicate source (and hence hash) values, but also to allow for the possibility of hash collisions. Even if your source values are guaranteed unique, this index should be non-unique. Other than that, this should be enough to let us construct a query to make the search more efficient:
DECLARE @search varchar(MAX) =
'The quick brown fox jumps over the lazy dog.';
SELECT Id, StringCol
FROM [dbo].[Table1]
WHERE
(StringHash = CONVERT(binary(16), HASHBYTES('MD5', @search))) AND
(StringCol = @search);
You’ll notice I’ve still included the StringCol = @search predicate in the WHERE clause — this is to ensure correct results of the query due to hash collisions. If all we did was compare the hash values, we could end up with extra rows in the results. Here’s the execution plan of the query above:

We got an index seek, which was the main thing we were looking for. The Key Lookup is expected here, because we have to compare the original values as well, and those can only come from the base table. You can now see why I said this method only works for moderately-to-highly selective queries, because the key lookup is required, and if too many rows are being selected, these random operations can kill performance (or the optimizer may revert to a table scan). In any event, we now have an optimal query, and even with the key lookups happening, the estimated cost was 0.0066, an improvement by over 500x on this smallish table.
Takeaways
I’m sure at this point you can think of several other uses for this methodology; it can be applied to large binary fields, too. You could even implement it for cases where the column could be indexed directly (say, varchar(500), with most of the values taking up nearly all the allowed space), but maybe you don’t want to — hashing the data might save a significant amount of storage space, of course at the expense of code complexity and a bit of query execution time.
While hashing data is nothing new, this technique exploits hashing to greatly improve the efficiency of data comparisons. I’ll leave it as an exercise for the reader to try the JOINing scenario I mentioned above — if you do, try it using computed columns first for maximum learning — you’ll find that this technique also improves the queries, as long as the join cardinality remains low (like in the 1-table scenario, to control the number of key lookups).
1 While I haven’t tested this in SQL Server either using HASHBYTES or a CLR function, there are implementations of certain hash algorithms in processor hardware itself. This may be of benefit to reduce CPU usage, possibly at the expense of storage depending on the algorithms in question.